转自 智慧型運算芯世界
1.主頻
主頻,即 CPU 核心工作的時脈頻率(CPU Clock Speed),單位為 MHz 或 GHz。通常所說的某某 CPU 是多少兆赫指的就是 CPU 的主頻。
注意:很多人認為 CPU 的主頻就是其運作速度,其實不然。
CPU 的主頻表示在CPU 內數位脈衝訊號震蕩的速度,主頻和實際的運算速度有一定的關係,但目前還沒有一個確定的公式能夠定量兩者的數值關係,因為CPU 的運算速度還與CPU 的管線數目、快取大小、指令集、CPU 的位數等指標有關。
2.外頻
外頻是 CPU 的基準頻率,單位是 MHz,是 CPU 與主機板之間同步運作的工作頻率(系統時脈頻率)。絕大部分電腦系統外頻也是記憶體與主機板之間同步運作的頻率。
3.前端匯流排
前端匯流排(Front Side Bus,FSB)是 AMD 公司推出 K7 CPU 時提出的概念,是將 CPU連接到北橋晶片的匯流排,決定 CPU 與記憶體資料交換的速度。
資料傳輸最大頻寬取決於所有同時傳輸資料的寬度和傳輸頻率,即資料頻寬=(FSB×資料位元寬)/8。例如 64 位元的 CPU,前端匯流排是 800MHz,則它的資料傳輸最大頻寬是6.4GB/s。常見的前端匯流排頻率有 266MHz、333MHz、400MHz、533MHz、800MHz、1066MHz、1333MHz 等,前端匯流排頻率越大,表示 CPU 與記憶體之間的資料傳輸速率越高,更能充分發揮 CPU 的效能。夠大的前端匯流排可以保障有足夠的資料供給 CPU。較低的前端匯流排無法供給足夠的資料給 CPU,限制了 CPU 效能的發揮,成為系統瓶頸。
外頻與前端匯流排的差別:前端匯流排的速度是 CPU 與記憶體之間資料傳輸的速度,外頻是CPU 與主機板之間同步運作的頻率。也就是說,100MHz 外頻特指數位脈衝訊號在每秒鐘震盪一千萬次;而64 位元處理器100MHz 前端匯流排指的是每秒鐘CPU 可接受的資料傳輸量是100MHz×64b/8 = 800MB/s。
4.倍頻
倍頻,全名為倍頻係數,是 CPU 主頻與外頻的比值。原先沒有倍頻概念,CPU 主頻和系統匯流排的速度是一樣的,但 CPU 的速度越來越快,倍頻技術也就應運而生。
CPU 主頻的計算方式為:主頻 = 外頻 × 倍頻。顯然,當外頻不變時,提高倍頻,CPU 主頻也就提高了。每一款 CPU 預設的倍頻只有一個,主機板必須能支援這個倍頻。因此在選購主機板和 CPU 時必須注意這一點,如果兩者不匹配,系統就無法運作。俗稱的超頻就是透過設定倍頻係數,CPU 工作頻率超過 CPU 主頻。
5. CPU 的位元和字長
在數位電路和電腦技術中採用二進位,只有 0 和 1,無論是 0 還是 1 在 CPU 中都是一“位”。
CPU 在單位時間內(同一時間)能一次處理的二進位數的位數叫字長。能處理字長為8 位元資料的 CPU 通常叫 8 位元 CPU。同理,32 位元 CPU 就能在單位時間內處理 32 位元二進位資料。
位元組和字長的區別:英文字元用 8 位元二進位可以表示,所以將 8b 稱為一個位元組。 CPU字長是不固定的,8 位元 CPU 一次只能處理 1B,而 32 位元 CPU 一次就能處理 4B,64 位元 CPU 一次只能處理 8B。
6.快取
快取(Cache)是位於 CPU 與記憶體之間的暫存器,容量比記憶體小,存取速度比記憶體快。 Cache 中的資料實際上是記憶體中的一小部分,當電腦工作時,CPU 需要重複讀取相同的資料區塊,如果每次都從記憶體中讀取,由於CPU 速度遠高於記憶體速度,則記憶體成為電腦工作的瓶頸,Cache 正是在這種情況下出現的。
Cache 運作原理:當CPU 要讀取一個資料時,首先從Cache 中查找,如果找到,就立即讀取並送給CPU 處理;如果沒有找到,就從速度相對慢的記憶體中讀取,同時把這個資料所在的資料區塊調入Cache 中,以便日後能夠快速地從Cache 中讀取該數據,而不必再去讀記憶體。
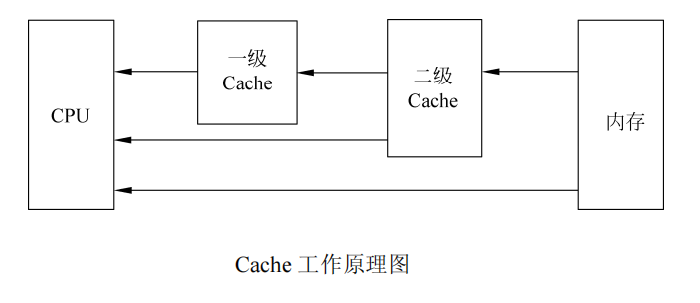
這樣的讀取機制使CPU 讀取Cache 的命中率非常高(多數CPU 可達90%左右),也就是說CPU 下一次要讀取的資料90%都在Cache 中,只有大約10%需要從內存讀取,這樣可以大幅節省CPU 讀取資料的時間。
CPU 核心整合的快取稱為一級快取(L1 Cache),主機板上整合的快取稱為二級快取(L2 Cache)。一級快取可以進一步分為資料快取(D-Cache)和指令快取(I-Cache),分別用來存放資料和執行這些資料的指令,可以同時被CPU 訪問,能夠減少爭用Cache 造成的衝突,提高處理器效能。
7.指令集
CPU 依靠指令完成計算和控制各元件的工作,每款 CPU 在設計時就規定了一系列與其硬體電路相配合的指令系統。指令集的強弱也是 CPU 的重要指標,指令集是提高 CPU效率的有效工具之一。
從電腦體系結構講,指令集可分為複雜指令集與精簡指令集兩部分。目前常見的Intel CPU 以及 AMD CPU 均為採用 X86 架構的複雜指令集。
而從具體運用來看,Intel 公司的MMX(Multi Media Extended)、SSE、SSE2(Streaming-Single instruction multiple data-Extensions 2)和AMD 公司的3DNow!等都是x86 架構CPU的擴展指令集,分別增強了CPU 的多媒體、圖形、影像和Internet 等的處理能力。
8. CPU 核心與 I/O 工作電壓
從 Pentium 開始,CPU 的工作電壓分為核心電壓和 I/O 電壓兩種,核心電壓即驅動CPU 核心晶片的電壓,I/O 電壓指驅動 I/O 電路的電壓。 CPU 的核心電壓小於等於 I/O 電壓。核心電壓依 CPU 的生產流程而定,一般製作製程越先進,電壓越低;I/O 電壓一般在 1.6~5V 之間。 CPU 的工作電壓有明顯的下降趨勢,低工作電壓有三個優點:
(1)使 CPU 的總功耗降低,系統的運作成本相應降低,電池可以工作更長時間,對於便攜式和移動系統來說非常重要。
(2)功耗降低,發熱量減少,運轉溫度不高的 CPU 可以與系統更好的配合。
(3)是提高 CPU 主頻的重要因素之一。
9.製造工藝
製造製程是指積體電路內電路與電路之間的距離。 1995 年以後,晶片製造製程從 0.5μm、0.35 μm、0.25μm、0.18μm、0.15μm、0.13μm、90nm、65nm、45nm,發展到目前的28nm、15nm、7nm、5nm。
先進的製造流程可以在相同的面積上整合更多的晶體管,並降低功耗,從而減少發熱量,使CPU 實現更多的功能和更高的性能;使CPU 核心面積不斷減小,在相同面積的晶圓上可以製造出更多的CPU 產品,進而降低CPU 的售價。
10.超流水線與超標量
在解釋超流水線與超標量前,先了解管線(Pipeline)。
管線是 Intel 公司在 80486 CPU 中開始使用的。流水線工作方式就像工業生產上的組裝流水線,透過增加硬體實現。例如要預取指令,就增加取指令的硬體電路,在CPU 中由5、6 個不同功能的電路單元組成一條指令處理管線,並將一條指令分成5、6 步,再由這些電路單元分別執行,各步驟的工作在時間上重疊,從而提高CPU 的運算速度。
超級流水線透過細化流水、提高主頻,使得在一個機器週期內完成一個甚至多個操作,其實質是以時間換空間。例如 Intel Pentium 4 的管線長 20 階。管線的步(級)越長,完成一條指令的速度越快,能適應主頻較高的 CPU。但管線過長也帶來一定的副作用,很可能會出現主頻較高的 CPU 實際運算速度較低的現象。
CPU 內建多條管線同時執行多條指令,每時脈週期內可以完成一條以上的指令,這種設計叫做超標量(Superscalar)技術。
11. SMP
SMP(Symmetric Multi-Processing,對稱多處理結構)是指在電腦上匯集了一組結構相同的處理器(多 CPU),各 CPU 共享記憶體以及匯流排。在高效能主機板和伺服器中常見,例如執行 UNIX 作業系統的伺服器可支援最多 256 個 CPU。
12.多核心
多核心是指單晶片多處理器(Chip Multiprocessors,CMP)。 CMP 由美國史丹佛大學提出,其想法是將大規模平行處理器中的 SMP 整合到同一晶片內,各個處理器並行執行不同的進程。從體系結構角度來看,SMP 比 CMP 對處理器資源利用率高,在克服延遲影響方面更具優勢。
而 CMP 相對 SMP 的最大優勢在於其模組化設計的簡潔性。複製簡單、設計容易,指令調度也更簡單。同時,SMP 中多個執行緒對共享資源的爭用也會影響其效能,而CMP 對共享資源的爭用則少得多,因此當應用程式的執行緒級並行性較高時,CMP 效能一般優於SMP 。此外,在設計上,更短的晶片連線使 CMP 比長導線集中式設計的 SMP 更容易提高晶片的運作頻率,從而在一定程度上起到性能優化的效果。
13.多(超)線程技術
每個正在運行的程式都是一個進程。每個行程包含一到多個執行緒。執行緒是進程中可以獨立完成一定功能的指令段。
多執行緒技術是指從軟體或硬體上實作多個執行緒並發執行的技術。具有多線程能力的電腦因有硬體支援而能夠在同一時間執行多個線程,進而提升整體效能。具有此能力的系統包括對稱多處理機、多核心處理器以及晶片級多處理(Chip-Level Multithreading)或同時多執行緒(Simultaneous Multithreading,SMT)處理器。
超線程(Hyper-Threading,HT)技術是Intel P4 CPU 開始出現的技術,利用特殊的硬體指令把兩個邏輯核心模擬成兩個實體晶片,讓單一處理器能進行線程級並行計算,進而相容於多執行緒作業系統和軟體,減少CPU 的閒置時間,提高CPU 的運作效率。雖然採用超線程技術能同時執行兩個線程,但它並不像兩個真正的 CPU 那樣,每個 CPU 都有獨立的資源。當兩個執行緒都同時需要某一個資源時,其中一個要暫時停止,並讓出資源,直到這些資源閒置後才能繼續。因此超線程的效能並不等於兩個 CPU 的效能。另外,含有超線程技術的 CPU 需要晶片組、軟體支援才能發揮該技術的優勢。
14. NUMA 技術
NUMA 即非一致存取分佈共享儲存技術,是由若干透過高速專用網路連接起來的獨立節點所構成的系統,各個節點可以是單一的 CPU 或是 SMP 系統。在 NUMA 中,Cache 的一致性有多種解決方案,需要作業系統和特殊軟體的支援。